2024年度国际语音通讯协会年会(Interspeech)将于9月1日-5日在希腊举办。Interspeech是国际语音通信协会ISCA组织的语音研究领域顶级会议之一,也被称为全球最大的综合性语音信号处理盛会,在世界范围内享有极高声誉,并受到全球各地语言领域人士的广泛关注。会议网址:https://interspeech2024.org/
我校计算机学院蒙古文智能信息处理技术国家地方联合工程研究中心共有8篇论文被Interspeech 2024录用,内容涵盖语音翻译、回声消除、多模态语音增强等,以下为论文简述。
Parameter-Efficient Adapter Based on Pre-trained Models for Speech Translation
作者:陈楠,王勇和,飞龙*
单位:内蒙古大学
摘要:
多任务学习 (MTL) 方法利用语音和机器翻译中的预训练模型,显著推进了语音到文本的翻译任务。然而,它引入了大量的参数,导致训练成本增加。大多数参数高效微调 (PEFT) 方法仅训练额外的模块以有效减少可训练参数的数量。尽管如此,在多语言语音翻译设置中,PEFT 方法导致的可训练参数的增加仍然不可忽略。在本文中,我们首先提出了参数共享适配器,与常规适配器相比,它将参数减少了 7/8,而性能仅下降了约 0.7% 。为了在模型参数数量和性能之间取得平衡,我们提出了一个基于神经网络搜索 (NAS) 的模型。实验结果表明,适配器的性能最接近微调,而 LoRA 的性能最差。
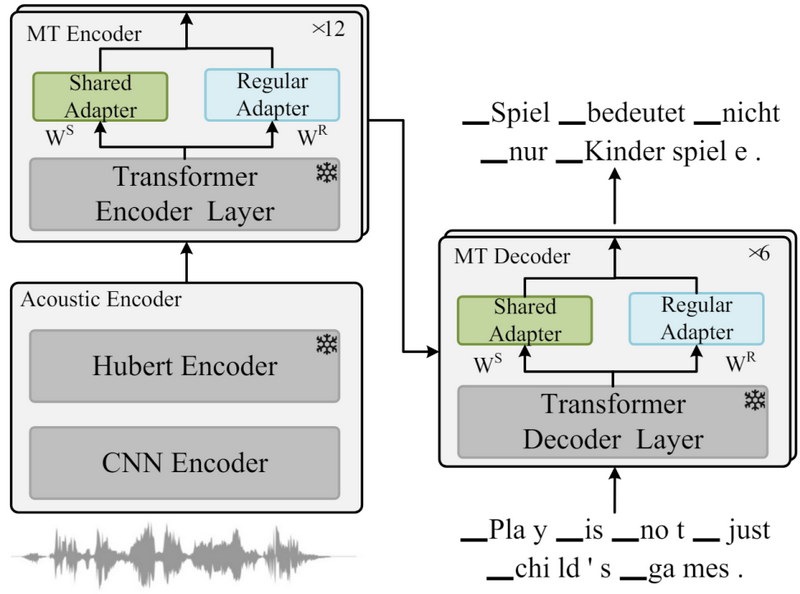
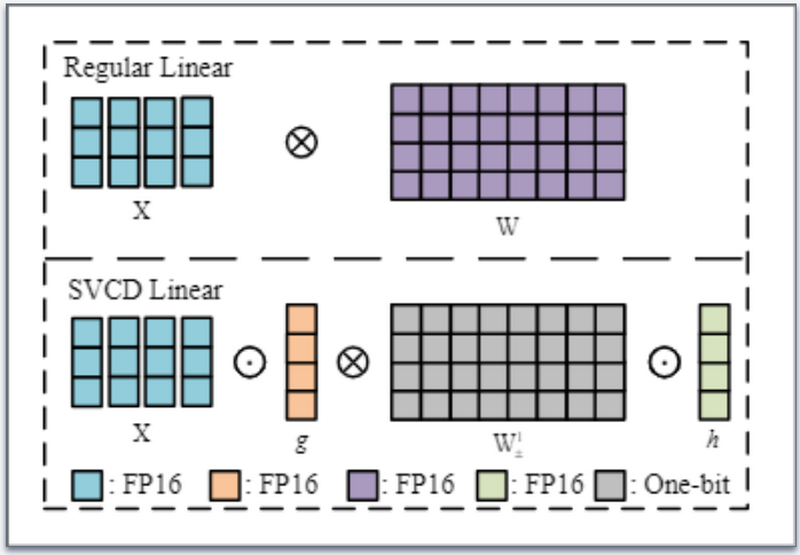
Sign Value Constraint Decomposition for Efficient 1-Bit Quantization of Speech Translation Tasks
作者:陈楠,王勇和,飞龙*
单位:内蒙古大学
摘要:
语音到文本的翻译对于将语音输入转换为不同语言的文本输出至关重要。虽然结合语音和机器翻译预训练模型可以提高翻译质量,但也会增加参数数量,从而导致模型训练和部署的硬件成本大幅增加。为了应对这一挑战,我们提出了一种基于符号值约束分解 (SVCD) 的线性层 1 位量化模型。SVCD 将线性层的权重矩阵近似为符号矩阵和两个可训练向量,以较小的空间成本保留了更高的信息容量。此外,我们利用知识蒸馏将原始微调模型的能力转移到量化模型。实验结果表明,解码器的注意力模块对于量化语音翻译模型的性能至关重要。
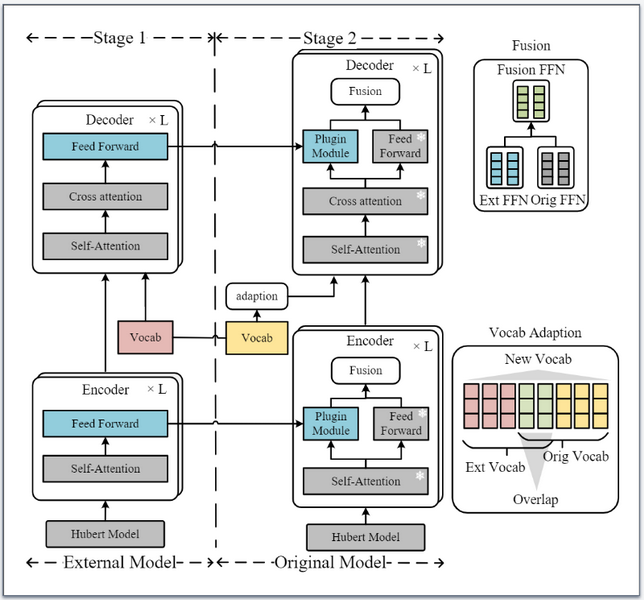
Knowledge-Preserving Pluggable Modules for Multilingual Speech Translation Tasks
作者:陈楠,王勇和*,飞龙
单位:内蒙古大学
摘要:
多语言语音翻译任务通常采用重新训练、正则化或重采样方法来添加新语言。重新训练模型会显著增加训练时间和成本。此外,使用现有的正则化或重采样方法来平衡新语言和原始语言之间的性能可能会导致灾难性的遗忘。这会降低现有语言的翻译性能。为了缓解上述问题,我们将新语言的知识存储在其他模型中。然后,我们将它们作为可插入模块引入现有的多语言语音翻译模型中。这种方法不会显著增加训练成本,也不会影响现有模型的翻译性能。实验结果表明,我们的方法提高了新语言的翻译性能,而不会影响现有的翻译任务。
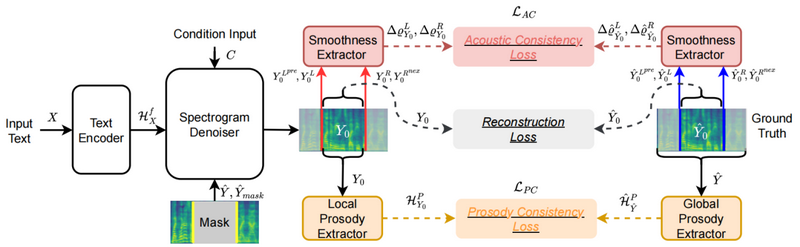
FluentEditor: Text-based Speech Editing by Considering Acoustic and Prosody Consistency
作者:刘瑞,席嘉甜,江子越,李海洲
单位:内蒙古大学
摘要:
基于文本的语音编辑(TSE)技术旨在通过修改输入文本内容来编辑输出音频,并非直接编辑音频本身。尽管基于神经网络的TSE技术已经取得了很大进展,但当前技术主要集中在减少编辑区域生成的语音片段与参考目标之间的差异,而忽视了其在上下文和原始语句中的局部和全局流畅性。
受到传统单元选择语音合成架构的启发,本文提出了一种流畅语音编辑模型FluentEditor,在TSE训练中引入流畅性感知的训练准则,分别从声学和韵律两个方面提升编辑边界处的平滑度。具体来说,声学一致性约束(The Acoustic Consistency Loss)旨在平滑编辑区域与其相邻声学片段之间的流畅过渡,使其与真实音频一致;而韵律一致性约束(The Prosody Consistency Loss)则旨在确保编辑区域内的韵律属性与原始语句的整体风格保持一致。在VCTK上的主观和客观实验结果表明,FluentEditor模型在自然性和流畅性方面均优于所有先进的基线方法。音频样本和代码可在https://github.com/Ai-S2-Lab/FluentEditor获取。
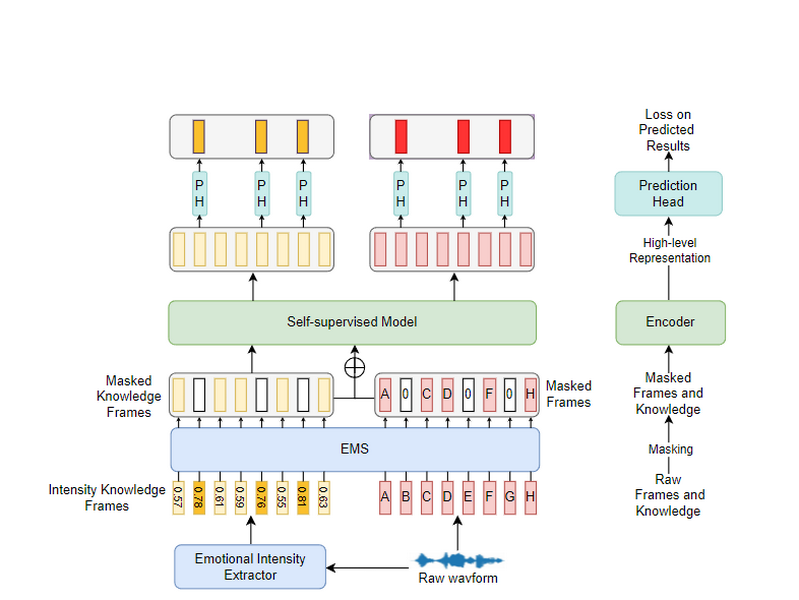
Emotion-Aware Speech Self-Supervised Representation Learning with Intensity Knowledge
作者:刘瑞,马泽宁
单位:内蒙古大学
摘要:
语音自监督学习(SSL)在各种下游任务中显示出相当大的功效。然而,目前流行的自监督模型往往忽略了与情感相关的先验信息,从而忽视了通过语音中的情感先验知识来提高情感任务理解能力的潜力。在本文中,我们提出了一种利用强度知识进行情感感知语音表征学习的方法。具体来说,我们利用已建立的语音情感理解模型提取帧级情感强度。随后,我们提出了一种新颖的情感掩码策略(EMS),将情感强度纳入掩码过程。我们选择了两个基于 Transformer 和 CNN 的代表性模型,即 MockingJay 和非自回归预测编码(NPC),并在 IEMOCAP 数据集上进行了实验。实验证明,在 SER 任务中,我们提出的方法所得到的表示优于原始模型。
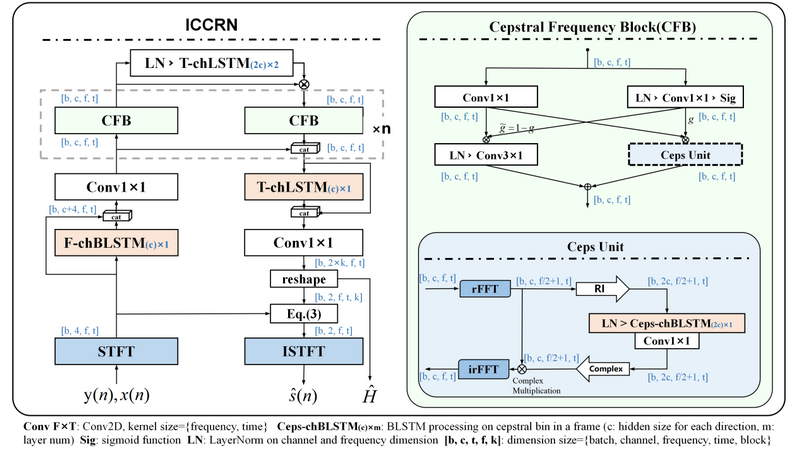
Deep Echo Path Modeling for Acoustic Echo Cancellation
作者:赵飞,张成刚,何树林,刘晋江,张学良
单位:内蒙古大学,内蒙古民族大学
摘要:
声学回声消除(AEC)是一种关键的音频处理技术,它可以消除麦克风输入中的回声,从而实现良好的全双工通信。近年来,深度学习在推进AEC方面显示出巨大的潜力。然而,深度学习方法在推广到复杂环境方面面临挑战,尤其是在训练中没有表现出来的不可见的条件下。在此论文中,我们提出了一种基于深度学习的方法来预测时频域中的回声路径。具体来说,我们首先在没有近端信号的单讲通话场景下估计回声路径,然后利用这些预测的回声路径作为辅助标签来训练有近端信号双讲通话场景的模型。实验结果表明,我们的方法优于强基线模型,并对不可见的声学场景表现出良好的泛化能力。通过使用深度学习估计回声路径,这项工作提高了在复杂条件下的AEC性能。
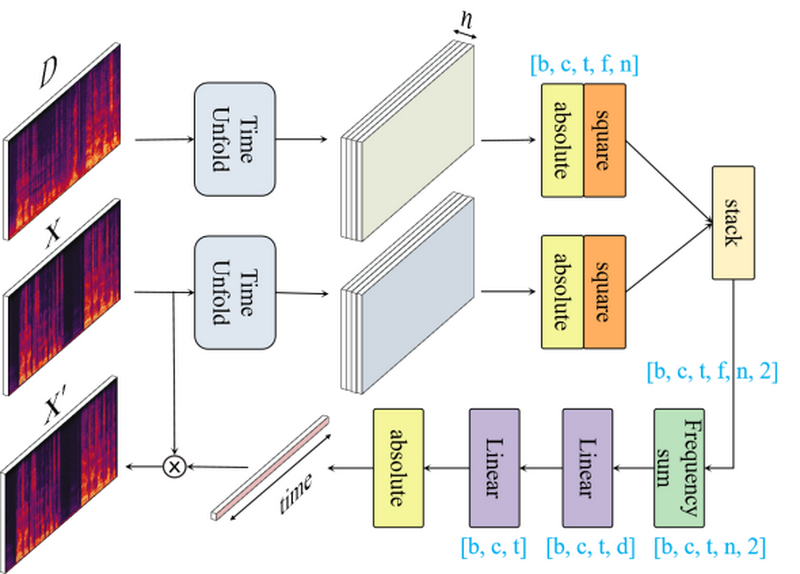
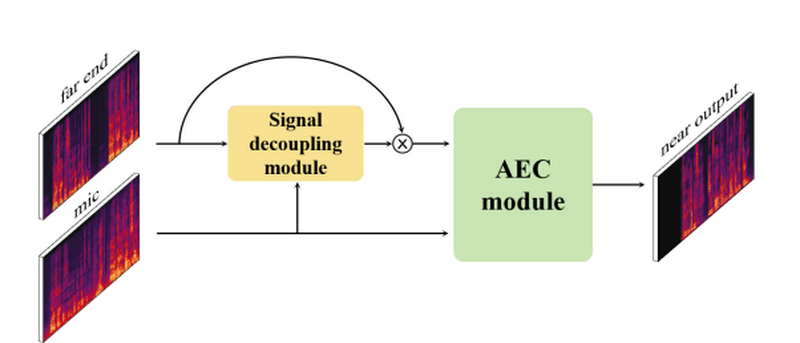
SDAEC: Signal Decoupling for Advancing Acoustic Echo Cancellation
作者:赵飞,刘晋江,张学良
单位:内蒙古大学
摘要:
在基于深度学习的声学回声消除方法中,神经网络隐式学习回声路径以消除回声。然而,在低信噪比条件下,麦克风信号和参考信号之间的巨大能量差异阻碍了网络的能力,导致性能较差。在这项研究中,我们提出了一种基于信号解耦的单耳声学回声消除方法,称为SDAEC。具体地,我们对参考信号和麦克风信号的能量进行建模,以获得能量比例因子。然后将参考信号乘以该能量比例因子,然后输入后续回声消除网络。这种方法降低了后续回声消除步骤的难度,从而提高了整体消除性能。实验结果表明,该方法提高了多个基线模型的性能。
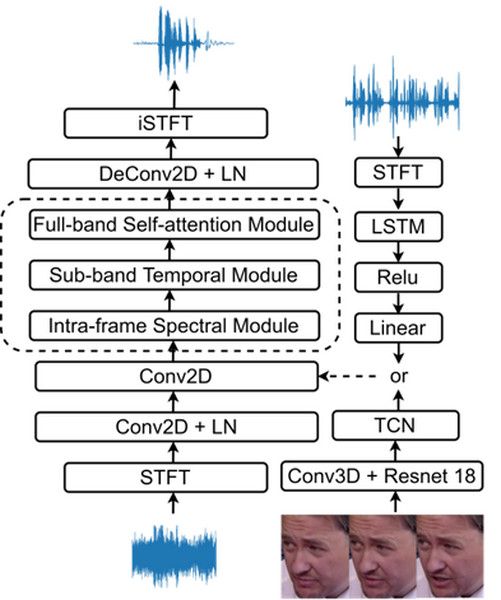
Unified Audio Visual Cues for Target Speaker Extraction
作者:武天赐,何树林,潘佳慧,黄海锋,莫志坚,张学良
单位:内蒙古大学、联想
摘要:
目标说话人抽取旨在从其他干扰说话人的语音中分离目标说话人的语音。通常,采用预录制的语音或面部视频作为辅助信息引导神经网络关注到目标说话人。现有的方法使用这些线索中的一种或通过注意力机制将两者融合,从而产生目标说话人的融合特征。虽然这两种线索都代表相同的说话人,但角度却并不相同。音频线索记录了说话人的音色特征,而唇部动作则代表同步特征。为了融合不同线索的优势并缓解线索之间的冲突,我们提出了一种统一的目标说话人抽取网络,称为Uni-Net,该网络采用分治的策略,将音频和视频线索融合到不同的网络中,以利用每种线索的独特信息。通过不同线索抽取得到的语音作为先验信息,进一步由后处理网络进行细化。我们在公共的VoxCeleb2数据集上进行实验,结果表明,Uni-Net相比于基线方法达到了最优的性能。
(供稿:计算机(软件)学院 编辑:刘阳 审核:刘雪峰)