近日,我校计算机学院(软件学院)刘瑞、张怀文研究员团队3篇论文被ACM MM 2024录用。ACM MM 2024也称为第32届ACM国际多媒体大会,英文全称The 32nd ACM International Conference on Multimedia (ACM MM),是CCF推荐的A类国际会议。ACM MM 2024将于2024年10月28日至11月1日在澳大利亚墨尔本举行。本次录用的3篇论文研究内容涵盖对话语音合成、跨模态检索和模态增强语义建模等,以下为论文简述。
图1 ACM MM 2024会议官网
01生成式对话语音合成
题目:Generative Expressive Conversational Speech Synthesis
作者:刘瑞1,胡一帆1,任意2,殷翔2,李海洲3
单位:1:内蒙古大学,2:字节跳动,3:香港中文大学(深圳)
简介:
对话语音合成(CSS)旨在在用户-代理(User-Agent)对话设置中以适当的说话风格表达目标话语。现有的CSS方法采用有效的多模态上下文建模技术来实现移情、理解和表达。然而,他们往往需要设计复杂的网络架构,并精心优化其中的模块。此外,由于包含脚本化录制风格的小规模数据集的局限性,它们通常无法模拟真实的自然对话风格。为了解决上述问题,我们提出了一种新颖的生成式表达式CSS大模型系统,称为GPT-Talker。我们将多轮对话历史的多模态信息转换为离散的标记序列,并将它们无缝集成,形成一个全面的用户-代理对话上下文。利用 GPT 的强大功能,我们预测了代理响应的标记序列,其中包括语义和风格知识。之后,富有表现力的对话语音由对话丰富的 VITS 合成,以向用户提供反馈。
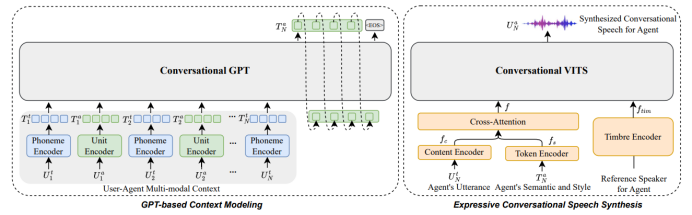
图2 GPT-Talker模型结构,包括对话GPT和对话VITS
此外,我们制作了一个名为NCSSD的大规模自然CSS数据集,该数据集包括即兴风格的自然录制的对话语音和从电视节目中提取的对话。它包括中文和英文两种语言,总持续时间为236小时。

图3 NCSSD数据集构建过程
我们对 NCSSD 的可靠性和 GPT-Talker 的有效性进行了全面的实验。主观和客观评估都表明,我们的模型在自然性和表现力方面明显优于其他最先进的CSS系统。代码、数据集和预训练模型可在以下网址获得:https://github.com/AI-S2-Lab/GPT-Talker。
02基于多实例多标签的文本运动跨模态检索
题目:Multi-Instance Multi-Label Learning for Text-motion Retrieval
作者: 杨洋,曹力元,时浩宇,张怀文
单位: 内蒙古大学
简介:
文本三维运动序列检索是一项重要的跨模态任务,它旨在检索语义上与给定查询文本相似的运动序列。现有的方法主要利用单个嵌入来表示和对齐文本和运动序列。然而,运动序列通常包含多个具有复杂语义的原子运动,其语义很难通过单个全局嵌入精确捕获。此外,原子运动还会同时发生,耦合在一起。这进一步对有效对齐文本和运动序列提出了重大挑战。
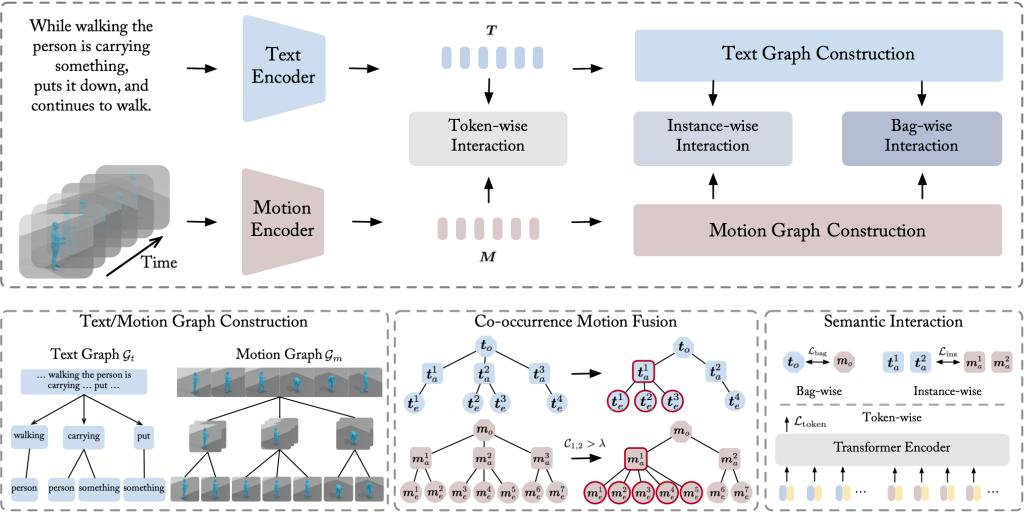
图4 多粒度语义交互方法
为了应对以上挑战,我们将文本三维运动序列检索视为一个多实例多标签学习问题,其中运动序列被视为原子运动的包,文本被视为相应短语的包。为了解决多实例多标签学习问题,我们提出了一种新的多粒度语义交互方法,该方法可以在不同层级对齐文本和运动序列。具体来说,多粒度语义交互方法最初将查询和动作序列分解为三个层级:字符、实例和包。我们利用图神经网络显式地建模它们的语义相关性,并在这些各自的层级上进行语义交互,精确地捕获多个粒度的语义。为了识别和建模同时发生的原子运动,我们测量运动之间的帧语义一致性,然后融合和交互一致的运动以改进它们的表示。最后,我们利用字符、实例和包级的语义交互来全面对齐文本和动作序列。所提出的方法在两个广泛使用的基准数据集取得了显著的改进。
03面向细粒度三维人体运动检索的模态增强语义建模方法
题目:Modal-Enhanced Semantic Modeling for Fine-Grained 3D Human Motion Retrieval
作者:时浩宇,张怀文
单位:内蒙古大学
简介:
文本到三维人体运动检索是一项重要的跨模态检索任务,旨在通过自然语言描述检索出语义相似的运动序列。传统方法在训练和测试阶段依赖于原始的粗粒度文本描述,这种描述缺乏对动作细节和相关身体部位的精确描述,导致跨模态对齐困难。此外,运动序列中包含连续的细微动作,这些动作往往发生在身体的局部,且变化幅度较小,传统方法难以准确识别和分辨这些细微的动作。
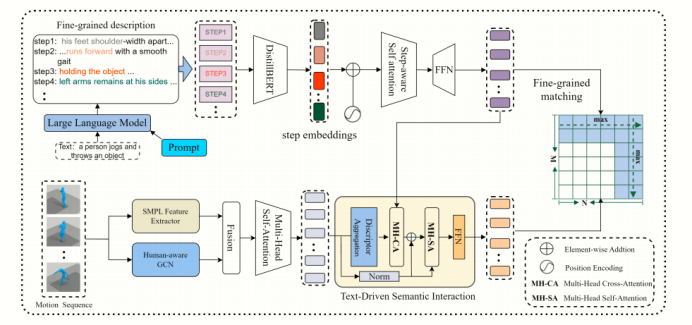
图5 模态增强的语义建模方法
为了应对上述挑战,我们提出了“模态增强的语义建模”(MESM)方法,该方法分别从文本和人体运动两个模态进行语义增强。具体来说,在文本表示方面,MESM利用大语言模型将原始的粗粒度文本扩展成细粒度的文本描述,并通过设计合适的提示信息,确保文本描述按照动作的发生顺序详细描述相关身体部位的运动。在运动表示方面,MESM采用图卷积网络来对人体关节点进行建模,增强不同关节之间的空间依赖关系,同时聚合有代表性的运动特征,从而提升了模型对细微动作的捕捉能力。最终,通过对增强后的多模态特征进行细粒度对齐,实现高效的检索性能。实验结果表明,该方法有效地对齐了文本和运动模态的数据,显著提升了文本和三维人体运动的检索性能。
(素材来源:科学技术处 编辑:李文娟 审核:刘雪峰)